Motivation
I play World of Warcraft. Being a Linux user requires me to run this in Wine, a Windows API translation layer. While Wine is continuously improving, its performance in Direct3D games still leaves much to be desired.
Having very little familiarity with Direct3D or the Wine codebase, I decided to spend a weekend diving straight into the deep end to make things better.
Finding the bottleneck
We have a bit of a head start regarding where to look- since the
game runs well on Windows, we know that our bottleneck is likely to
be CPU-side or synchronization related (either in NVIDIA’s GL
driver, or in wine). Using tools such as nvidia-smi
reveals that our GPU utilization is fairly low (30-40%), which
reaffirms my suspicions.
But before touching a single line of code, we need visibility. What problem are we trying to solve? Where is the slowness coming from?
One of my favourite tools for answering these questions is perf, a
performance counter based profiler for Linux. perf
gives us insight into what the distribution of CPU time is-
importantly, which functions are the hottest.
That’s all we need to get started here. I opened WoW and traveled
to an area of the game that performed much worse under Wine- running
at ~14fps, versus ~40fps in Windows. perf sheds a light
into where our time was spent:
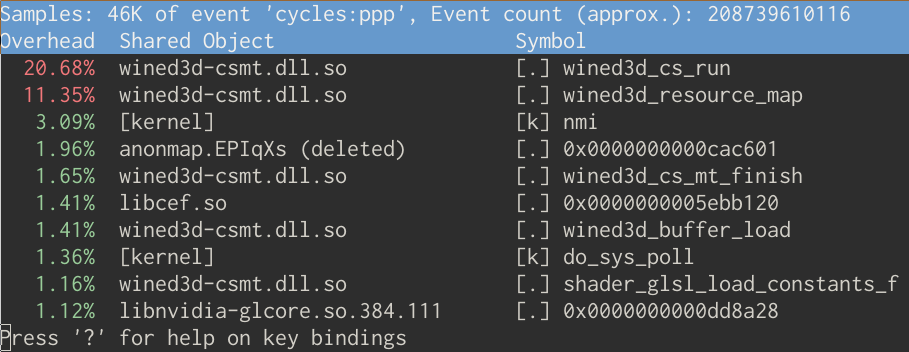
Let’s analyze some of the top offenders, and figure out at a high level how to make things better.
Firstly, wined3d_cs_run leads us
head first into how Wine’s Direct3D implementation works internally.
wined3d is the library responsible for translating
Direct3D calls into OpenGL calls. Newer versions of wine use a
command stream to execute the OpenGL calls after
translation from their D3D equivalents. Think of this as a separate
thread that executes a queue of draw commands and state updates from
other threads. This not only solves the issue of the multithreaded
OpenGL story being nightmarish, but lets us parallelize more
effectively and ensures that the resulting GL calls are executed in
some serialized ordering.
Right, back to wined3d_cs_run. This is the core of
the command stream- it’s just a function that busy-waits on a queue
for commands from other threads. Some brief analysis of the source
code indicates that it does no real work of interest, other than
invoke op handlers for the various commands. But at least we know
about command streams now!
wined3d_resource_map is where
things get interesting. Fundamentally, it’s a function that maps a
slice of GPU memory into the host’s address space, typically for
streaming geometry data or texture uploads. Given a “resource”
(which is typically just a handle into some kind of GPU memory), it
does the following;
- Waits for the resource to no longer be held by any other command in the command stream.
- Adds an operation to the command stream to map a section of the
given resource into the host’s address space.
- For resources backed by GL buffers, this is accomplished using
glMapBufferRange.
- For resources backed by GL buffers, this is accomplished using
- Waits on a response from the command stream thread, containing a pointer to the address.
Intuitively, this makes a lot of sense. We need to wait for the command stream to finish before this function can return- otherwise, where would we get our pointer from? We can’t execute any OpenGL commands to map the resource off the command thread, so we’re forced to wait.
What we’re up against
I needed to learn more about how WoW uses its buffer maps to figure out what we could do here.
Enter apitrace. By
using apitrace to wrap the execution of WoW under wine,
I could intercept the D3D9 calls it was making prior to hitting
wined3d.
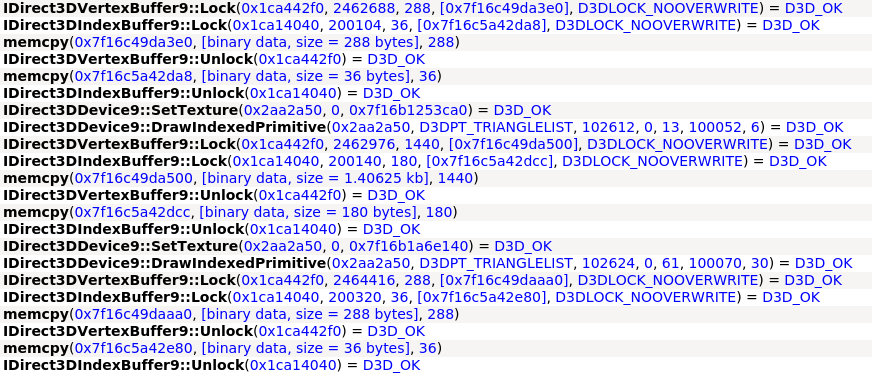
Using this data, I was able to construct a simple model of how WoW renders dynamic geometry;
- Lock (map) vertex and index buffers with the
D3DLOCK_NOOVERWRITEflag, which promises not to overwrite any data involved in an in-flight draw call.- This allows the GPU to avoid waiting for the prior draw call to finish before returning the buffer.
- If a buffer is full, map it with the
D3DLOCK_DISCARDflag, which invalidates the buffer’s contents.- This can either assign the buffer to a new, unused location, or do nothing at all if the buffer is not being used for any draw calls.
- Copy vertex data into the newly mapped region using
memcpy. - Unlock the buffers.
- Execute
DrawIndexedPrimitiveon the new segment of vertex data in the buffer. - Repeat back to 1, moving your offset further into the buffer.
This technique works very well for ensuring that we should never have to wait for the GPU. In fact, Microsoft recommends it.
But, the story with wine is less than ideal. In practice, this is what happens:
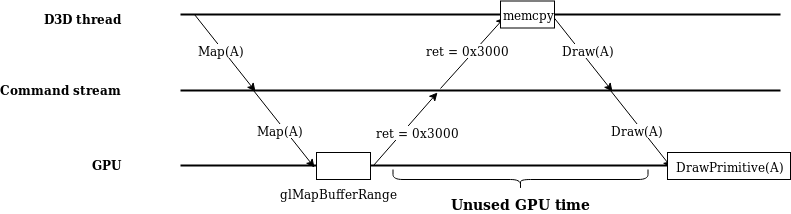
This is a textbook example of a pipeline stall.
By waiting for the command stream thread and the mapping thread to
synchronize, we’re wasting time that could instead be spent
dispatching more draw calls to the GPU. If the command stream thread
is busy, the D3D thread could be waiting a nontrivial amount of time
for a response! Not only this, but glMapBufferRange-
the actual OpenGL call used to map a buffer- is
slow. Actually mapping the buffers, even when
synchronization is explicitly disabled, takes a long time.
Cease and persist
We could solve our problem handily by not having to wait for the CS thread. The question is- how?
Suppose we had access to a large, persistently mapped buffer in the host address space. We never had to unmap it to make a draw call, and writes to it were coherently visible to the GPU without any GL calls.
- If the flag
D3DLOCK_NOOVERWRITEwas provided, then we can return the address of the last persistent mapping for that buffer.- Just pointer arithmetic- no need to talk to the command stream thread!
D3DLOCK_NOOVERWRITEfundamentally lets us ignore synchronization.
- If the flag
D3DLOCK_DISCARDwas provided, then we can remap the buffer to an unused section of persistently mapped GPU memory.- A bit trickier to implement- we’ll need an allocator in order to avoid fragmentation.
- Otherwise, we need to wait for the GPU to finish using the
buffer (i.e. talk to the command stream thread).
- This is fine for our purposes, since this (common) streaming geometry technique doesn’t need to wait for buffers.
Enter the holy grail: ARB_buffer_storage. This lets
us allocate an immutable section of GPU memory, and allow persistent
(always mapped) and coherent (write-through) maps of it. We’re
effectively replacing the role of the driver here, which would
handle DISCARD (INVALIDATE in GL) and
NOOVERWRITE (UNSYNCHRONIZED in GL) buffer
maps itself.
This is an AZDO (approaching zero driver overhead) style GL extension. If you’re interested, check out this article by NVIDIA.
Introducing wine-pba
wine-pba (short for persistent buffer allocator) is
a set of patches I’ve written that leverages
ARB_buffer_storage to implement a GL-free GPU heap
allocator, vastly improving the speed of buffer maps.
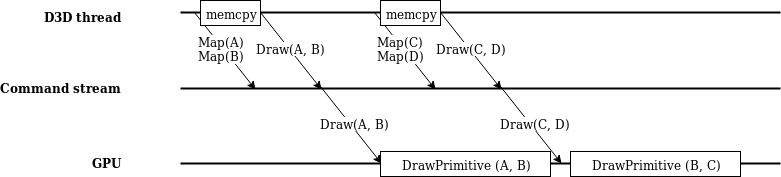
At device initialization, a very large OpenGL buffer is allocated. This buffer is governed by a simple re-entrant heap allocator that allows both the command stream thread and D3D thread to make allocations and recycle them independently from each other.
When a D3DLOCK_DISCARD map is made, the D3D thread
immediately asks the allocator for a new slice of GPU memory and
returns it. The command stream thread is sent an asynchronous
message informing it of the discard, with information on the new
buffer location so that future draw commands on the command stream
thread are aware. The command stream thread returns its old buffer
to the heap allocator when this happens, with a fence to ensure that
the buffer isn’t reused until it is no longer being used by the
GPU.
When a D3DLOCK_NOOVERWRITE map is made, we can just
return the buffer’s mapped base address plus the offset desired.
Sweet!
Otherwise, the old synchronous path is undergone- except this
time, without requiring a call to glMapBufferRange
(only waiting on a fence).
So, what does this look like?
Benchmarks
Unfortunately, WoW does not have great public-facing benchmarking
functionality. I settled for using the console command
/timetest 1, which measures the average FPS when taking
a flight path- no ground NPCs or players are loaded while in-flight
to reduce variation in test runs. Additionally, I eyeballed the
average idle FPS in various common in-game locations.
These benchmarks were performed on patch 7.3.5 running with 4x SSAA at a resolution of 2560x1440. The CPU is an i5-3570k, and the GPU is a GTX 1070. The graphics preset “7” was chosen (as recommended by the game).
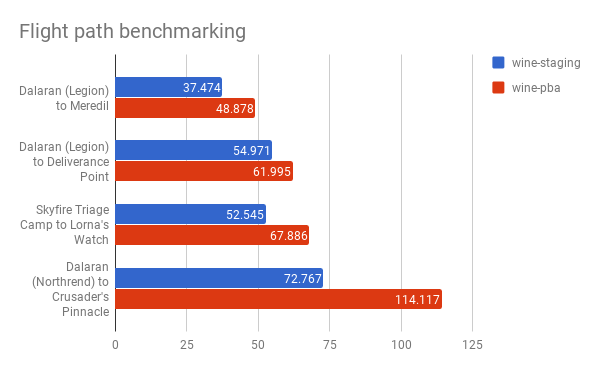
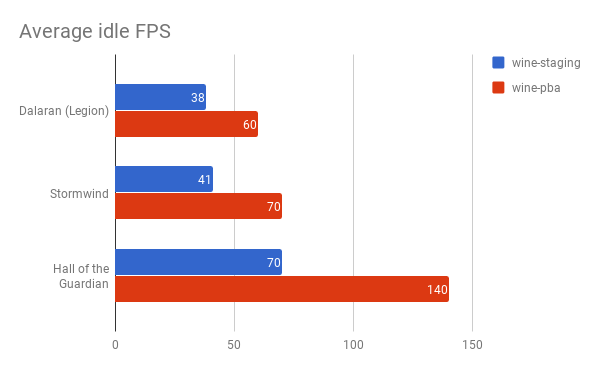
I’m fairly satisfied with the results demonstrated by this benchmark. I hope to update this post with additional frame timing data from a GL intercept tool.
What’s left
- Segregated free lists
- A simple optimization that will allow us to obtain free buffers faster.
- I plan to bin regions using powers of two.
- Chunked GL buffer allocation
- Making a large allocation at device initialization time makes startup slower, even though modern GPUs use virtual memory.
- Instead of allocating one massive buffer approaching the size of available VRAM, consider using multiple buffers and generating new buffers on-demand.
- Infrequently of course, since a round-trip to the CS thread would be required.
- Polish
- A few minor hacks are currently used to get wined3d to use persistent maps effectively.
- GL extension support is taken for granted in many cases, checks need to be added.
- Testing
- Unit tests for the heap allocator would be nice to have.
Conclusion
You can find an early prototype of wine-pba at github.com/acomminos/wine-pba. This is far from production quality, and makes several (erroneous) assumptions regarding implementation capabilities. I hope to mainline this once the patchset becomes more mature.
I hope you found this post valuable. I look forward to digging deeper into how to use AZDO techniques to improve wine performance, particularly for uniform updates and texture uploads.
← home